
Transformers and Attention Mechanism
Published:
This is a Blog Post is a part of background research I did for my master thesis.
Transformers and Attention Mechanism
The attention mechanism is a way to weight the importance of regions within a sequence. The transformer is an architecture based solely on the attention mechanism and was first introduced for language and machine translation tasks in Vaswani et al., 2023. The transformer gained popularity and showed great results in this area, which also inspired the vision community.
While Convolutional Neural Networks (CNNs) are the dominant architecture for vision tasks, transformers outperform them in many cases. The advantages of transformers lie in their ability to learn dependencies of distant locations effectively since they fit the structure of GPUs and can calculate the attention layers in parallel. In contrast, deep CNNs have layers that depend on the previous layers. Transformers have shown good performance in object detection and text-to-image tasks, and the attention mechanism works well in video tasks since the temporal information can be used efficiently. Since this study engages strongly with these tasks, I dedicate an introduction to transformers.
This section presents the attention mechanism formulation and transformer architecture as described in Vaswani et al., 2023. Then, I show the modifications for vision tasks, and finally, I will discuss transformers in video tasks.
Attention in Language
The transformer architecture, shown in Figure 1, consists of an encoder and decoder. The attention calculation is performed in the multi-head self-attention block. Self-attention computes a representation of a single sequence by computing a weighted sum for each token over the other tokens, as shown in Figure 2.
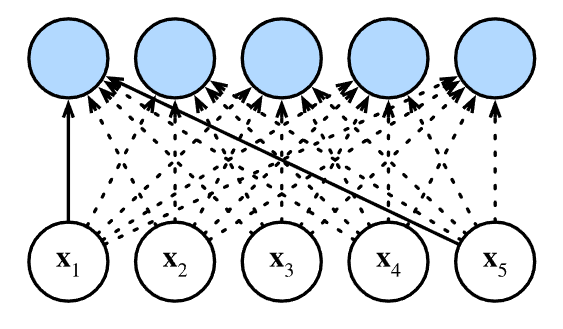 Figure 2: Self attention from Zhang et al., 2023
Figure 2: Self attention from Zhang et al., 2023
At the encoder, the self-attention block receives a query and key-value pair from the previous encoder layer as input. It calculates the similarity between the query and the key by performing a dot product multiplication, scaling the result, and then applying a softmax function to get values in the range of 0 to 1. The result is then multiplied with the value, interpreted as the weight of this value—the larger the weight, the more attention the value receives. The calculation is shown in Equation 1.
\(\text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^{T}}{\sqrt{d_{k}}}\right)\cdot V\) Equation 1: Attention calculation formula
This calculation is performed h times with different linear projections of the queries, keys, and values, which is why it is called multi-head attention. The multi-head and dot product usage in the attention function are where the compatibility of the transformer with GPU structure works well, as the attention function can be calculated in parallel, making the process faster and more efficient. Then, we have skip connections employed between the sub-layers and also layer normalization, followed by a fully connected feed-forward block.
The decoder has a similar structure with an additional multi-head attention block that receives the key-value from the encoder output and the query from the preceding multi-head attention block. The first multi-head attention block in the decoder gets the keys, queries, and values from the output of the previous decoder output and has a masking mechanism that ensures the token in the current position has access only to previous output tokens. Another important aspect of transformers is the positional encoding. Since self-attention computes the representation of each token over the other tokens in parallel, it doesn’t preserve the position of the token in the sequence. To retain this information, positional encoding is associated with each token.
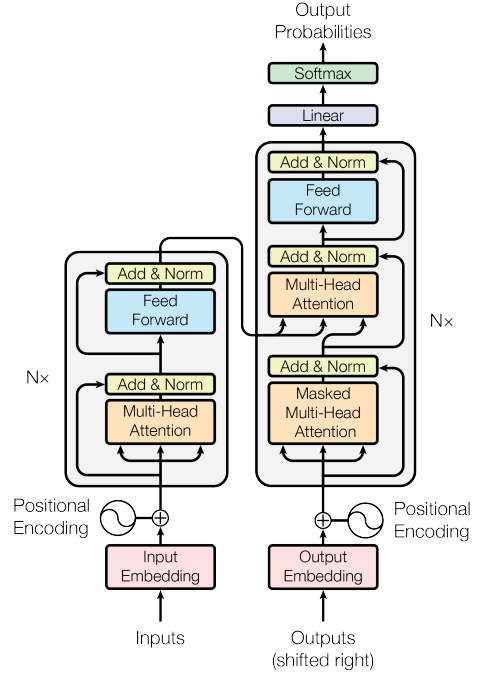 Figure 1: A standard Transformer architecture from Vaswani et al., 2023. On the left is the encoder and on the right is the decoder.
Figure 1: A standard Transformer architecture from Vaswani et al., 2023. On the left is the encoder and on the right is the decoder.
Attention in Vision
After the significant influence of Transformers in language models, there were attempts to use transformers for computer vision tasks. Dosovitskiy et al., 2021 introduced Vision Transformers (ViT) for classification tasks. Their strategy involved creating patches from the input image and treating these patch embeddings as tokens. The architecture is shown in Figure 3. They reshaped the input image of size H×W×C into a sequence of N=HW/P² patches, where each image patch of size (P,P) was flattened into a length of P² × C. In ViT, the positional embeddings were trainable and added to the patch embeddings because these embeddings are not preserved during self-attention. Vision Transformers models outperformed CNN models when trained on very large datasets. Spatial self-attention focuses on the relationships between pixel locations within feature maps, enhancing similar regions. In contrast, cross-attention connects pixels with external inputs, such as text, to establish relevant associations.
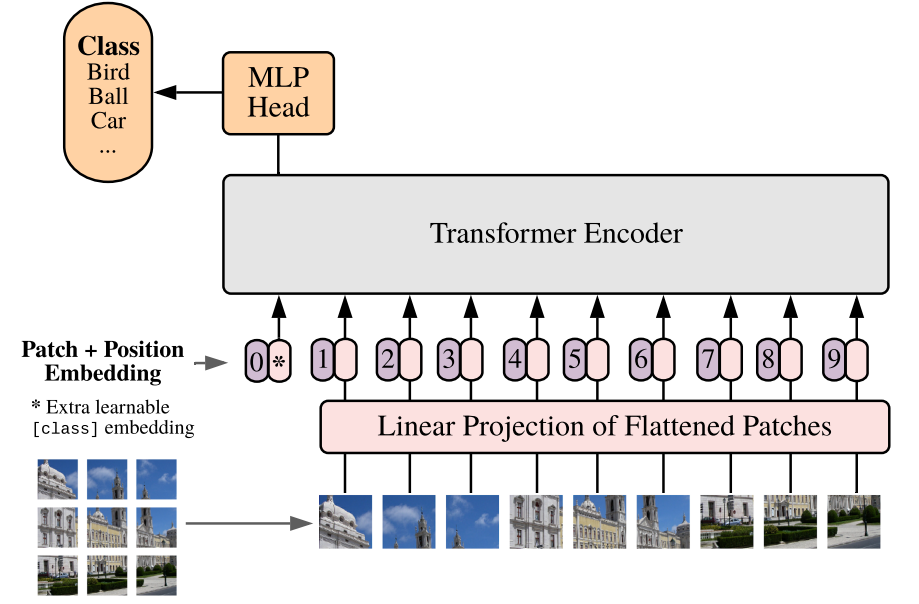 Figure 3: Vision Transformer Model Overview, as presented at Dosovitskiy et al., 2021 for classification task.
Figure 3: Vision Transformer Model Overview, as presented at Dosovitskiy et al., 2021 for classification task.
Spatial and Temporal Attention
Spatial attention aims to answer the question of where to pay attention, while temporal attention addresses when to pay attention. Both are crucial when dealing with video processing tasks. In some cases, these are combined to create a spatiotemporal attention mask, while in others, they are computed separately, and the information is integrated for the task.
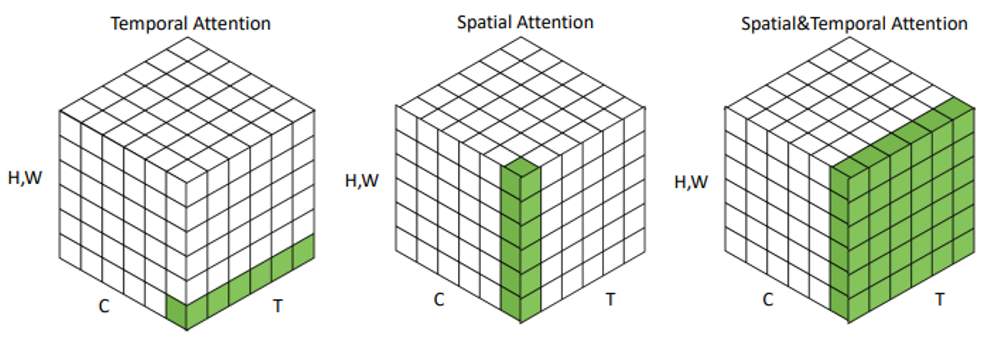 Figure 4: Adapted from Guo et al., 2022, the green color indicates where attention is used.
Figure 4: Adapted from Guo et al., 2022, the green color indicates where attention is used.
References
- Author, A. (Year). Title of the paper/book. Journal/Publisher. URL or DOI if available.
- Vaswani, A., et al. (2023). Attention is All You Need. Neural Information Processing Systems. https://arxiv.org/abs/1706.03762
- Dosovitskiy, A., et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations. https://arxiv.org/abs/2010.11929
- Zhang, X., et al. (2023). Dive into Deep Learning. Deep Learning Press. URL or DOI.
- Guo, Y., et al. (2022). Temporal and Spatial Attention Mechanisms in Deep Learning. Journal of Visual Communication. URL or DOI.