
Diffusion Models for Virtual Try-On
Published:
Virtual Try-On what is the goal?
what are the chalenges? (1) how to preserve the small but important details of garments while warping the garment to match various body shapes, and (2) how to preserve the identity of the person without leaking the original garments that the person was wearing to the final result.
first I’ll introduce the approach before diffusion models, then with diffusion models and finally adjustments for video. here is the CVPR 2024 Workshop on Virtual Try-On: https://www.youtube.com/watch?v=h9_JwgNVrbg&t=2s here is the awesome-virtual-try-on github repo: https://github.com/minar09/awesome-virtual-try-on
VITON
VITON, proposed in 2018, is an image-based virtual try-on approach relying solely on plain RGB images without leveraging any 3D information. Its objective is to synthesize a photo-realistic new image by seamlessly overlaying a product image onto the corresponding region of a clothed person.
Clothing-Agnostic Representation
A clothing-agnostic representation is introduced, consisting of a comprehensive set of features describing various characteristics of a person. These features include pose, body parts, face, and hair. Pose information is explicitly modeled using a pose estimator (OpenPose), representing the pose as the coordinates of 18 keypoints. Each keypoint is transformed into a heatmap, with a neighborhood around the keypoint filled in. These heatmaps are then stacked into an 18-channel pose heatmap.
A human parser computes a human segmentation map and converts it into a mask. Additionally, the human parser extracts the RGB channels of face and hair regions to incorporate this information when generating new images. Finally, these three feature maps are resized to the same resolution and concatenated to form a clothing-agnostic person representation ( p ).
Pose Estimator: OpenPose

Human Parsing: Look Into a Person
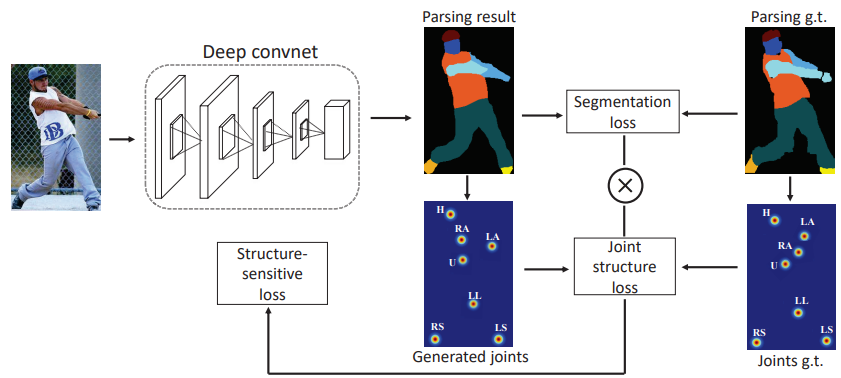

Synthesizing the Reference Image
Conditioned on this representation ( p ) and the target clothing image ( c ), a multi-task encoder-decoder network generates a coarse synthetic clothed person in the same pose wearing the target clothing item, along with a corresponding clothing region mask. The encoder-decoder architecture is based on U-Net with skip connections. The loss function combines a perceptual loss and an L1 loss.
Loss Function
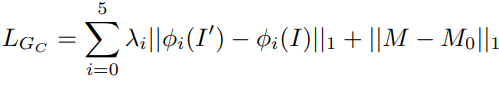
Here, ( \phi ) indicates the feature map, ( I’ ) the generated image, ( I ) the reference image, ( M ) the segmentation mask of the clothing region, and ( M_0 ) the ground truth mask predicted from ( I ). Missing details, such as text or logos, are refined in the subsequent steps.
Wrapping
Details from the target clothing image are directly borrowed to fill in the coarse sample’s generated region. To adapt the clothing item to the human pose and body shape, thin plate spline (TPS) transformation is estimated using shape context matching. The clothing region mask guides the warping process to handle deformations.
TPS Wrapping This is interesting. pick n points on the contours of a shape. for each p_i consider the n-1 vectors obtained by connecting p_i to all other points. the set of these vectors is a rich description og the shape. the coarse histogram is the shape context. then you match each point from the two shapes. the matching can be done using the hungarian method. to minimize the cost of matching first choose a transformation that wraps the eges of the known shape to the unknown. given the set of correspondences a transformation can be estimated. it can be affine or thine plate spline (TPS). it solves a linear system of rquations. calculate the shape distance between each pair of points on the to shapes. use a nearest neighbor classifier to compare its shape distance to shape distance of known objects.
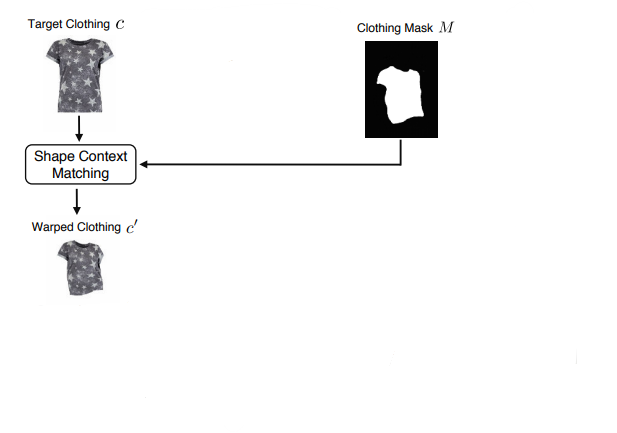
Refinement Network
A refinement network is trained to learn how to composite the warped clothing item onto the coarse image, ensuring the desired item is transferred with natural deformations and detailed visual patterns. This network generates a composition mask, indicating how much information is utilized from the warped clothing item and the coarse image.
Refinement

Diffusion Models for Virtual Try-On
M&M VTO: Multi-Garment Virtual Try-On and Editing the goal is different, its mixed and match, you can put the shirt and pants for example. full body task. This model takes garmet images, person image and text description. a single stage diffusion based model, UNet diffusion transformer, effective finetuning strategy, control using text input. a progressive training strategy where model training begins with lowerresolution images and gradually moves to higher-resolution ones during the single stage training. Rather than finetuning the entire model during post processing, we choose to finetune person features only. they used unet diffusion model transformer to isolate encoding of person features from the denoising process. we created text based labels representing various garment layout attributes, e.g., rolled sleeves, tucked in shirt, and open jacket. they said in previous works the cascade diffusion models fails to catch the fine details of the garments, plus the in which resolution to apply cross-attention for implicit wraping, cuz too downsamoling destroys details but in higher it is hard to converge.
Diffusion Model Applications
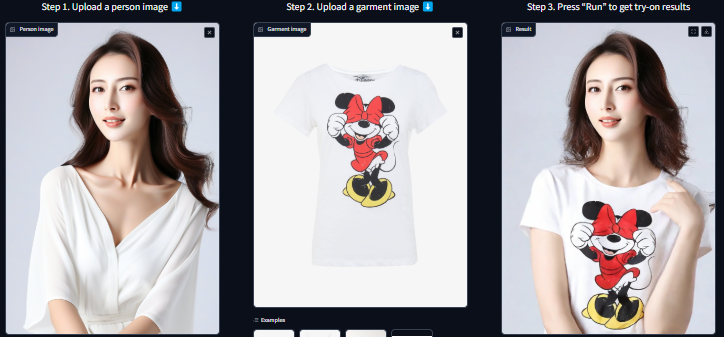
Using Kolors Virtual Try-On, sample results demonstrate that certain features (e.g., face, background, and top of the hair) remain consistent, while areas such as the neck, lower hair, and hand positions are transformed.
Sample Output
Video Diffusion Model for Virtual Try-On
Video-based try-on models face challenges in preserving garment details like fabric dynamics and achieving temporal consistency, especially with varying poses or occluded regions. Acquiring perfect ground truth data, such as two videos of different people wearing the same garment while moving identically, is difficult and expensive.
A recent breakthrough [Zhu et al., 2023] employs diffusion models that implicitly warp input garments under large pose gaps and heavy occlusion using spatial cross-attention. However, applying these methods frame-by-frame can result in severe flickering artifacts and temporal inconsistencies.
Addressing Temporal Consistency
Longer video generation faces challenges such as maintaining temporal consistency while adhering to computational and memory constraints. Prior approaches utilize cascaded methods, sliding window inference, or past-frame conditioning but often fail to generate consistent and artifact-free outputs.
Inspired by techniques in context modeling for LLMs, short-video generation models can be extended for long-video generation through temporally progressive fine-tuning schemes. For example, inflating the M&M VTO architecture with 3D convolution and temporal attention blocks enables maintaining temporal consistency in videos up to 64 frames long using a single network.
Conclusion
Traditional image virtual try-on approaches involve warping the target garment onto the input person and refining the result. For video try-on, past methods often rely on multiple networks to predict intermediate values like optical flow, background masks, and occlusion masks, making diffusion-based methods a promising alternative.